안녕하세요!
자연어분석 프로젝트
8주차 포스팅입니다 :)

지난 포스팅에서
최종 모델을 선정하고
모델을 학습시키는 것까지 진행했었는데요,
오늘은 Train Data 로 학습시킨
해당 모델을 이용해
Test Data 를 분석하고
결과값을 얻는 과정을
포스팅에 담아보겠습니다..!
Test Data 전처리 과정
모델 학습을 위해
Train Data 를 전처리 했던 것처럼
Train Data 역시도 같은 모양으로
전처리 과정을 거쳐야 하는데요,
일단, Load 함수를 통해
Test Data 를 가져옵니다..!

그 다음,
Tokenizer (Korean) 을 이용해
문장을 품사단위의 단어 요소들로
나누어줍니다.

토큰화 된 단어들을
Doc2Vec 함수에 넣어
문장/단락/문서간의 유사성을
찾아줍니다.
Train Data 를 활용해서
모델의 정확도를 파악할 때,
Dimension 을 25 로
지정하는 것이 가장 높은 정확도를 보였기 때문에
여기서도 같은 값으로 설정해주었습니다 :)

이렇게해서 생성된 document_vectors 열은
배열 형태의 값을 갖게 되는데요,
Array To Cloumns 함수를
배열을 각각의 열로 변환 해 줍니다!
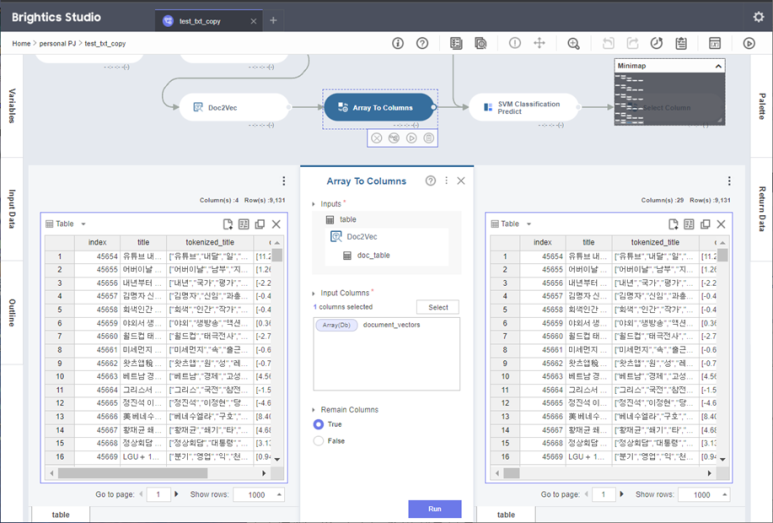
이렇게 하면 바로 모델에 입력할 수 있는
데이터 셋 형태를 갖추게 됩니다 ଘ(˵╹-╹)━☆
모델을 이용해 Test Data Topic 예측하기
그럼 이제 정말
결과를 얻어내는 일만 남았군요
⁽⁽◝( ˙ ꒳ ˙ )◜⁾⁾
SVM Classification Predict 함수에
학습시킨 모델과
전처리 한 데이터를 넣어주면
끝이라는 말이죠~!~!

위와 같이 테이블을
제 위치에 넣어주고
함수를 실행시키면
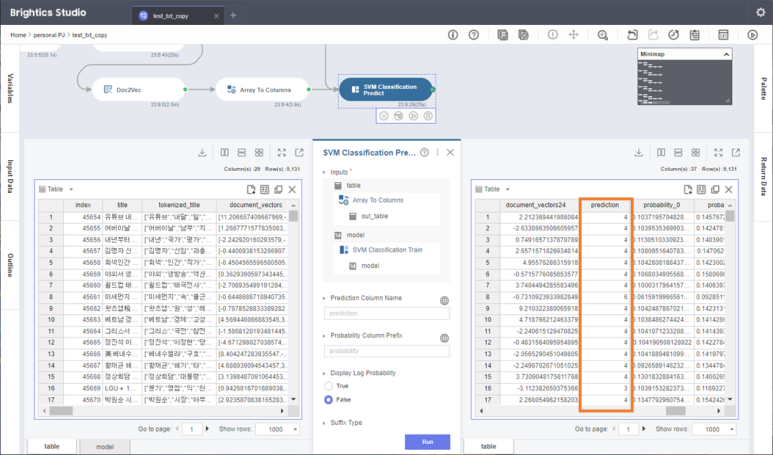
자잔~!
Prediction 이라는 열이 생성되면서
Topic 을 예측할 수 있습니다.
자, 여기서 대회 제출 양식을 확인하기위해
sample_submission 파일을
열어보시면
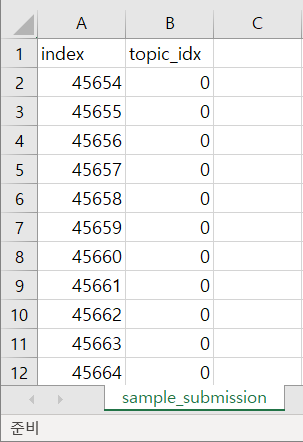
위와 같습니다.
SVM Classification Prediction 함수의
결과 값에서
index 와 topic_idx 값만
추출해야겠군요..!

prediction 열의 Alias 를
topic_idx 로 설정하여
두 열을 추출한 후,
download 버튼을 클릭하여
해당 테이블을 다운받아
제출하면 끝~!~!
(⑅´•⌔•`)*✲゚*。
오늘의 포스팅은 여기까지 입니닿ㅎㅎㅎ
그럼,, 앙뇨옹..!
* 해당 게시글은 Brightics 서포터즈 활동의 일환으로 작성되었습니다.
게시글 관련 문의 및 소통을 원하신다면 댓글을 남겨주세요 :)
브라이틱스 사용 중 문의사항은 brightics.cs@samsung.com 으로 연락주세요!
#삼성SDSBrightics #BrighticsStudio #BrighticAI #브라이틱스 #모델링 #코딩없이분석하기 #데이터분석 #군집분석 #군집분석모델 #Clustring #Clustering_without_coding #코딩없이군집분석모델링하기 #빅데이터 #데이터사이언티스트 #데이터분석툴 #데이터분석플랫폼 #데이터분석툴체험하기 #분석모델제작하기 #무료데이터분석툴 #오픈소스 #삼성SDS #삼성SDS서포터즈 #Brightics서포터즈 #Brightics서포터즈2기 #데이터사이언티스트 #DS #데이터컨설팅 #데이터컨설턴트 #Brightics서포터즈개인미션 #공공데이터수집 #자연어분석 #Text_Classification #데이터전처리 #모델생성 #모델비교 #분석모델정확도판단 #분석모델정확도비교
'SDS Brightics > Projects' 카테고리의 다른 글
| [삼성 SDS Brightics] 개인 분석 프로젝트 ୧(`•ω•´)୨ #9. 최종 모델 분석결과 제출하기 (0) | 2021.10.26 |
|---|---|
| [삼성 SDS Brightics] 개인 분석 프로젝트 ୧(`•ω•´)୨ #7. 최종 모델 선정 & 실행하기 (0) | 2021.10.12 |
| [삼성 SDS Brightics] 개인 분석 프로젝트 ୧(`•ω•´)୨ #6. 오류 해결 & 모델 실행하기 (0) | 2021.10.05 |
| [삼성 SDS Brightics] 개인 분석 프로젝트 ୧(`•ω•´)୨ #5. 모델 정확도 높이기 (0) | 2021.09.28 |
| [삼성 SDS Brightics] 개인 분석 프로젝트 ୧(`•ω•´)୨ #4. 오류 발생?! (1) | 2021.09.23 |