[삼성 SDS Brightics] 팀분석 프로젝트 ୧(`•ω•´)୨ #4.Kaggle Competition - 모델 완성 및 최종 보고서 작성

안녕하세요!
지난 주에는 One Hot Encoder 와 PCA 를
통해 효과적으로 데이터를 처리하는
방법을 설명드렸었는데요,
이번주는 분석의 정확도를 높이고
프로젝트를 마무리하는 과정을
포스팅 하도록 하겠습니다 :)
지난 주의 포스팅은 요 링크에서 확인하실 수 있답니다 :)
https://yslog99.tistory.com/entry/삼성-SDS-Brightics-팀분석-프로젝트-୧•ω•´୨-3Kaggle-Competition-모델-분석-및-수정하기-One-hot-encoder-PCA
[삼성 SDS Brightics] 팀분석 프로젝트 ୧(`•ω•´)୨ #3.Kaggle Competition - 모델 분석 및 수정하기 (One ho
안녕하세요! 벌써 방학이 다 끝나가는데요,, 방학기간동안 목적하셨던 바들은 많이 이루셨나요?! 저는 이룬것도, 못한것도 있지만 전반적으로 아주 바쁘게, 지금까지중에 가장 열심히 방
yslog99.tistory.com
지난번 포스팅이 PCA 를 이용하면
중요 요소를 추출할 수 있다고까지 설명을 드렸었죠?!
이번에는 PCA 를 어떻게 사용하는지
조금 더 자세한 설명을 드리도록 하겠습니다!
PCA 활용하기
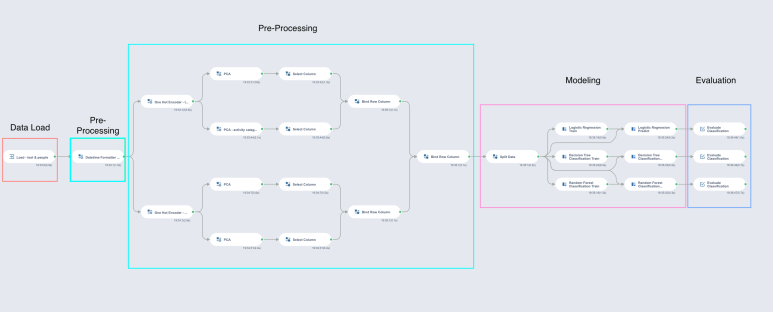
저희가 작성한 모델의 전체 미니맵은
위와 같습니다!
두번째 Pre-Processing (파란색) 블록을 보시면,
One Hot Encoder 와 PCA 가
둘씩으로 나눠져 시행되는것을
확인할 수 있는데요,
이는 One Hot Encoder 에서
데이터를 변환하는 과정에서
한 열에 있는 데이터가 여러 열로 분할되면서
데이터의 양이 아주 크게 늘어나는
문제가 있다고 했었잖아요?!
이를 해결하기 위한 방안으로
저희가 고안해 낸 방법이랍니다 :)
위와 같이 데이터를 여러 개의 Section 으로
나눠서 인코딩하고,
PCA 를 통해 인코딩 결과에서
중요 요소만을 뽑아온 뒤,
다시 합쳐 분석용 데이터셋을 만드는것이죠!

PCA 를 실행 한 후 Model 란에서
Explained variance 표 (빨간 박스) 를 확인해 보시면
네번째 요소까지는
Explained variance(설명 비율) 가
0.12 로 꽤 높은 비율을 보이다가,
다섯번째에서 0.0046으로
크게 감소하는 것을 확인하실 수 있는데요,
이를 통해 Number of Components (주황 박스) 에
설정할 값을 결정할 수 있습니다!
위와 같은 경우에는 4개로 설정하는 것이
바람직하겠군요!
이렇게 적당한 수의
중요 요소를 골라내고
이 데이터들을 모아서 학습을 시키면
더 효율적인 모델을 제작할 수 있습니다 :)
Bind Row Column 함수

그럼, 데이터는 어떻게 합치는가!?
Bind Row Column 함수를 이용하면
위와 같이, 데이터를 열 단위로 합병하여
하나의 테이블로 만들 수 있답니다 :)
이렇게 하면 테이블의 행의 갯수는 늘어나지 않고,
열의 갯수만 늘어나는 합병이 가능합니다
데이터를 합병하는 또 다른 방법으로는
Join 함수가 있는데요,
Join 함수는 왼쪽 테이블과 오른쪽 테이블에서
각 참조열을 기준으로 합병이 이루어지기 때문에
이렇게 하면 테이블의 열의 갯수는 늘어나지 않고,
행의 갯수만 늘어나는 합병이 가능합니다
두 합병방법의 차이를 확실하게 이해하고,
상황에 맞는 합병방식을 이용하는게 좋겠죠?!
ㅎㅎ
결과
데이터를 합병한 후에는,
2주차 포스팅에서 설명드린 바와 같이
3가지 모델을 실행 한 후, 결과를 확인 해 줍니다!

Model 정확도 변화
Logistic Regression
(PCA 전) 0.85 > 0.80 (PCA 후)
Decision Tree Classification
(PCA 전) 0.96 > 0.98 (PCA 후)
Random Forest Classification
(PCA 전) 0.98 > 0.98 (PCA 후)
Logistic Regression 의 정확도는 조금 감소했지만,
원래 가장 정확도가 낮은 모델이었기 때문에
미련은 없고,,,!
상대적으로 정확도가 높은
Decision Tree Classification 와
Random Forest Classification 모델이
정확도가 증가하는 추세를 보이고 있군요!!
아주,,,
만족스러운 결과였습니다,,ㅎㅎ
그럼., 오늘은 포스팅은 여!기!까!지!
앙뇨옹
(°▽°๑)– =͟͟͞͞ =͟͟͞
* 해당 게시글은 Brightics 서포터즈 활동의 일환으로 작성되었습니다.
게시글 관련 문의 및 소통을 원하신다면 댓글을 남겨주세요 :)
브라이틱스 사용 중 문의사항은 brightics@samsung.com 으로 연락주세요!
#삼성SDSBrightics #BrighticsStudio #BrighticAI #브라이틱스 #모델링 #코딩없이분석하기 #데이터분석 #군집분석 #군집분석모델 #Clustring #Clustering_without_coding #코딩없이군집분석모델링하기 #빅데이터 #데이터사이언티스트 #데이터분석툴 #데이터분석플랫폼 #데이터분석툴체험하기 #분석모델제작하기 #무료데이터분석툴 #오픈소스 #삼성SDS #삼성SDS서포터즈 #Brightics서포터즈 #Brightics서포터즈2기 #데이터사이언티스트 #DS #데이터컨설팅 #데이터컨설턴트 #Brightics서포터즈팀미션 #KaggleCompetition #캐글프로젝트 #캐글제출 #Brighitic캐글 #데이터전처리 #모델생성 #모델비교 #분석모델정확도판단 #분석모델정확도비교