[Samsung SDS Brightics] 데이터 사이언티스트? 데이터 분석? 그게 뭔데!? #01. 기초 개념편
안뇽하세요!
제가 열.심.히 데이터 분석 프로젝트를 업로딩 하고 있는데,
다들 잘 따라오고 계신가요!?
부디 제가 잘 하고 있는거였으면
좋겠구먼요...
오늘은 데이터 사이언티스트 라던가 DS 분야의 특징,
데이터 분석 방식, 데이터 분석의 순서 와 같은!
제가 프로젝트을 진행하면서 공부한 기초적인 개념들을 공유해볼까 합니다!

데이터 사인언티스트란?

Shelly Palmer 가 2015년에 발표한 해당 벤다이어그램에 따르면, 데이터 사이언티스트는 수학과, 컴퓨터 그리고 분야 전문성이 합쳐져 이루어져있는 분야를 의미합니다.
분야 전문성이라는건, 어떤 분야든 그곳에 전문적인 지식이 있어야 한다는 의미입니다!
의료면 의료계열에 대한 전반적인 지식을, 마켓팅이면 마켓팅에 대한 전문적인 지식을 가지고 있어야 한다는 것이죠!
컴퓨팅이랑 수학은 항상 같이 있던 분야니까 익숙한데,
분야 전문성이 조금 특이하게 느껴지시지 않나요?!
"데이터 분석하는 툴을 만드는 사람이라면, 코딩하는 사람일텐데 분야 전문성이 왜 필요하지?"
이렇게 말이죠.
하.지.만! 데이터 사이언티스트를 단순한 코딩 능력자라고 생각하시는건
아주 곤란하답니다!

데이터 사이언티스트는 데이터 분석 모델을 생성해서
유의미한 정보를 추출해 내야 하거든요!
이를 위해서
해당 분야에 맞는 전략적인 분석과
원하는 목표에 적합한 데이터를 수집하는 능력이 매우매우 중요 하답니다
(๑•̀ㅂ•́)و
데이터 사이언스(DS) 분야는?!?!
그렇다면!
데이터 사인언티스트(DS) 분야가 각광받고 있는 이유는 무엇일까요?!
전 세계적으로 연간 데이터의 양은 아주 크게 증가하고 있는데요,
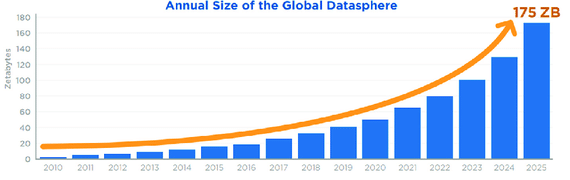
데이터의 양이 증가하는 만큼,
이러한 데이터를 효율적으로 활용하는 것 역시 매우 중요해지고 있습니다.
여기서 "데이터를 효율적으로 사용" 하기 위해
데이터 사이언티스트가 할 수 있는 일은 크게 두가지로 나누어집니다.
첫 번째는, 수학과 컴퓨팅 능력을 기반으로
데이터 분석의 정확도를 높이는 일입니다!
데이터 전처리, feature, 알고리즘 최적화등을 진행하여
정확도가 더 높은 모델을 만드는 것이죠!
두 번째는, 분야 전문성을 기반으로
데이터 분석을 더 효율적으로 할 수 있도록 하는 것입니다!
주어진 데이터를 어떻게 분석해야 있는지,
목표 달성을 위해 어떤 데이터가 필요한지,
분석한 결과를 어떻게 상업화 할 수 있는지 등을 판단하여
더 가치있는 정보를 산출해내기 위한 일을 하는것이죠.
분석 모델을 만드는 것은 아주 복잡하고 많은 과정을 거쳐야 하지만,
이렇게 생성된 모델을 실제로 활용하는 정도는 30% 밖에 안된다고 합니다!
이에 따라,
데이터 분석 기술이 발전하던 초반에는
데이터를 잘 분석하는 모델을 만들어내기 위한
수학 및 컴퓨팅 능력 (코딩 등) 이 매우 중요했다면,
이제는 실제 산업에서 쉽게 사용할 수 있고,
잘 활용할 수 있는 모델을 만들기 위한
분야 전문성이 점점 중요해지고 있죠 :)
데이터 분석의 순서
데이터 분석을 위해서는
크게
1. 주제 선정 (문제 정의)
2. 데이터 수집
3. 데이터 전처리
4. 데이터 모델링
5. 시각화 / 리포팅
의 단계를 거치게 됩니다!
1. 주제 선정 (문제 정의) 단계 에서는 분석 대상을 이해하고,
객관적이고 구체적으로 분석 대상을 정의합니다.
2. 데이터 수집 단계에서는 필요한 데이터 요건을 정의하고
데이터 소재를 파악하고 확보합니다.
3. 데이터 전처리 단계에서는 오류사항을 점검하고
데이터 구조 및 특성을 변경시킵니다.
4. 데이터 모델링 단계에서는 다양한 관점을 반영한 데이터 분석을 설계하고,
관련 테이블간의 관계를 설정해 모델링을 진행합니다.
5. 시각화/리포팅 단계에서는 다양한 유형의 데이터를 시각화하고
문제해결을 위한 인사이트를 도출합니다.
머신러닝을 이용한 데이터 분석의 종류
머신러닝을 이용한 데이터 분석은 크게 4가지의 종류로 나누어 질 수 있습니다.

예측의 참/거짓 판별이 가능한 경우,
예측 대상이 수치인 경우에는 회기 모델을 이용하고,
예측 대상이 카테고리인 경우세는 분류 모델을 이용합니다.
또한, 예측의 참/거짓 판별이 불가능한 경우에는
비숫한 부류끼리 묶는 경우에는 군집 모델을 이용하고,
이전의 데이터를 통해 연관성 있는 정보를 제공하는 경우에는 추천 모들을 이용합니다.
여기까지 잘 이해가 되셨나요?!
더 자세하게 적고싶지만 글이 너무 길어지는 것 같아,,
최대한 요약하고! 핵심만 뽑아서!
설명을 적어 보았습니다.
도움이 되셨길 바라며,
또 좋은 컨텐츠로 찾아뵙겠습니다ㅏ :)
앙뇽!
* 해당 게시글은 Brightics 서포터즈 활동의 일환으로 작성되었습니다.
게시글 관련 문의 및 소통을 원하신다면 댓글을 남겨주세요 :)
브라이틱스 사용 중 문의사항은 brightics@samsung.com 으로 연락주세요!
#삼성SDSBrightics #BrighticsStudio #브라이틱스 #모델링 #코딩없이분석하기 #데이터분석 #빅데이터 #데이터사이언티스트 #데이터분석툴 #데이터분석플랫폼 #데이터분석툴체험하기 #분석모델제작하기 #무료데이터분석툴 #오픈소스 #삼성SDS #삼성SDS서포터즈 #Brightics서포터즈 #Brightics서포터즈2기 #데이터사이언티스트 #DS #데이터컨설팅 #데이터컨설턴트#데이터분석기초개념 #데이터분석설명 #데이터분석이란? #데이터분석초보 #초보를위한간단설명